
Overcoming Challenges: Adopting Kubernetes for Efficient Application Deployment
Kubernetes tackles many problems, that we all in teh software branch had to face. It’s a battle proven initially developed by Google Container orchestration platform for endless scaling - horizontally and vertically.
Discover the Benefits: Why Your Company Should Embrace Kubernetes
So, why would you, as company, want to adapt Kubernetes?
Well, there are many good reasons to do that, that I will to explain to you in this blog. But I got to be honest with you, it for sure, comes at a cost.
Standardization and Time Savings: The Long-Term Benefits of Going Cloud Native
That cost is eventually overcome by the fact that going cloud native means standardization, which in return, means enormous time savings in the long term.
Kubernetes as is, is not much of a challenge from a view as a technical concept.
The Cloud Native Trail: Containerization and Learning Curves in Software Development
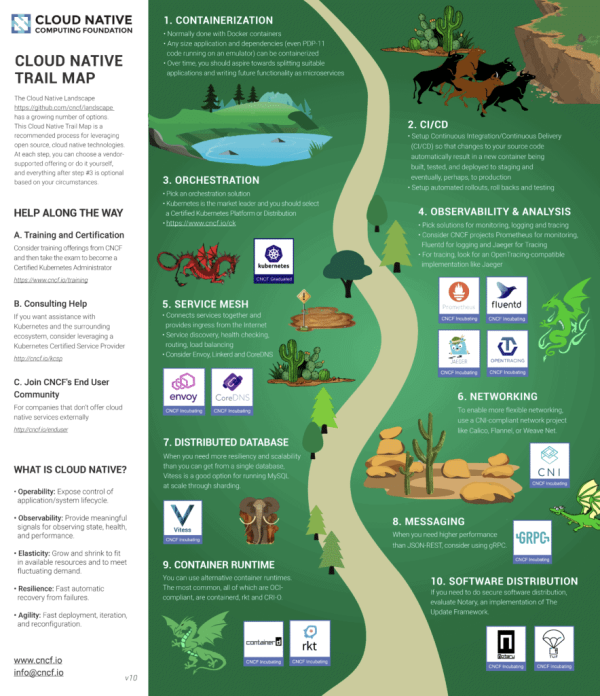
source: https://www.cncf.io/wp-content/uploads/2020/08/CNCF_TrailMap_latest-1.png
Furthermore it means changing your whole software development and lifecycle management.
Take a look at the cloud native trail map. You’ll need to start containerizing your applications.
Every step to get you cloud native will be a steep learning curve. You’ll earn rewards!
As I mentioned earlier Kubernetes brings standardization, which might already be its biggest selling point, although most people don’t seem to understand that at first sight.
I actually think, that this is why all like to go “Cloud”, be it be public, private oder any hybrid variants that you may encounter.
Kubernetes forces you to streamline all aspects of your software - from development to packaging, delivery and last but not least how it runs.
Kubernetes from an infrastructural point of view is just another iteration on virtualization of workloads.

source: https://kubernetes.io/docs/concepts/overview/
Can you understand what I am trying to tell you ?
It's a fundamental conceptual shift. One that doesn’t happen too often, but when it does it is only a matter of time until it is the de facto standard.
Don’t get me wrong, Virtual Machines were and always will be part of an infrastructure / server landscape.
But one of the many things that Kubernetes solves for you is scalability. Of course, you could always scale a server in some means. (Add more virtualized Hardware to it). But that of course doesn't make it highly available.
Ensuring High Availability: Exploring the Role of Master and Worker Nodes in Kubernetes
Kubernetes provides with two kinds of Nodes: Master and Worker Nodes.
Each has a distinct very specific use case.
Master Nodes control the worker nodes. Their sole purpose is to control the workload you’re throwing at your “Cluster”. It schedules the pods (workload) on you worker nodes. It does that in a way, if a worker nodes dies, has network problems or anything, that makes that worker node unavailable: in the best case, you wouldn’t even notice that. Why ? Because it will try to reschedule your workload that was supposed to run on an not anymore available worker node to other worker nodes that might still be around.
Same goes for Master Nodes. You can have as many, as you’ll like. But it gotta be an odd number. And please don't be foolish! Choose wisely about how many workers and masters you need.
Just to remind you:
In Kubernetes you ALWAYS want to make sure, to use an odd number of masters.
This means that 2 Masters is as good or bad as 4 or even 6 Masters!
Choose 1 Master for HA 3 or 5!
Why are you asking ?
You’re running with 4 masters a network incident isolates masters 1 and 2 from masters 3 and 4. In this scenario, every master knows that an incident occurred, but none of them knows what happened to the two missing masters — they could be offline, or simply inaccessible via the network.
This poses the following problem. Kubernetes masters need a majority quorum (more than 50%) to operate properly. However, in the above scenario, neither side has a majority. This forces the control plane into read-only mode where your apps continue to work but configuration changes are not allowed.
Consensus and Consistency: The Importance of an Odd Number of Kubernetes Masters
If you’d started with an odd number of masters (see below) and the same network partition occurred, one side would have a majority and would continue cluster operations as normal. This is why 3 is better than 4, and 5 is better than 6.
This is all to do with achieving consensus and consistency as quickly as possible.
Basically, all cluster changes need pushing to all masters to maintain a consistent view of the cluster. More masters means the time to consistency is longer. It’s a bit like deciding where to eat dinner — if there’s only three in the group it won’t take long to decide, but if there’s 33 in the group you could spend half the night deciding.
This is why, generally speaking, 3 and 5 are usually good numbers, with anything above 7 approaching slowdown territory.
Automating for Success: Why Kubernetes Drives the Need for Automation
Another key selling point on why you’d want to adapt Kubernetes is, because it forces you to do automatization. If you don’t automate your stuff, you’ll be lost and suffering.
There are so many great solutions to do that. You’ll probably want to use some kind of CI/CD approach to build and deliver your containers (ready to use build applications).
Logo Kubernetes by https://icons8.com/license










{kind=link}