Ende Februar diesen Jahres haben wir uns wieder zwei Tage Auszeit von unseren aktiven Kundenprojekten gegönnt, um neue Dinge auszuprobieren, unser Wissen im Team zu teilen und unser "Handwerk" in den Bereichen Softwareentwicklung, DevOps und agile Methoden zu trainieren.
Wobei uns ein digitaler Zwilling unterstützt
Ich habe dieses mal die Idee gehabt einen digitalen Zwilling unserer Projekte zu bauen. Ein digitaler Zwilling ist eine digitale Abbildung eines realen oder virtuellen Objekts. Für Interessierte gibt es auf Wikipedia eine umfangreiche Beschreibung des Begriffs. Digitale Zwillingen werden häufig in IoT Projekten eingesetzt um dort z.B. Anlagen oder Prozesse abzubilden, die Daten aller Sensoren zu sammeln und Aktoren zu steuern.
Unsere Herangehensweise
In unseren Projekten existieren allerhand Daten, deren Sammlung und Auswertung sich lohnt, um uns laufend zu verbessern und neue Erkenntnisse zu gewinnen. Begonnen haben wir dabei im Kopf des Benutzers und uns entsprechend überlegt, welche Informationen für einen Benutzer des Systems relevant sind und wie wir das User Interface gestalten. An dieser Stelle noch ein Dankeschön an unsere Kollegin Maja, die uns immer wieder mit ihrem Wissen zum Design Thinking ansteckt und uns trainiert, den Anwender immer in den Mittelpunkt unserer Arbeit zu stellen!
In unserem Team, bestehend aus Christian, Christian und mir (Gerhard) haben wir recht flott einen ersten Entwurf skizziert!
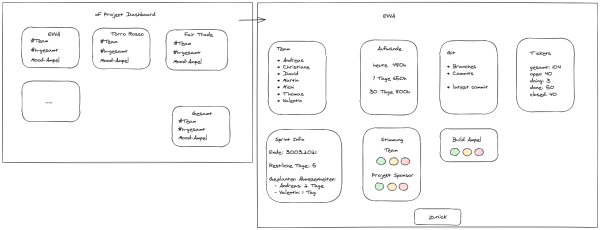
In zwei Tagen zum Digitalen Zwilling
Nachdem wir Daten aus unterschiedlichen Systemen zusammentragen wollen, haben wir uns dazu entschlossen mittels Apache Kafka einen Datenbus für die Integration der einzelnen Systeme einzusetzen. Und um die Daten in Echtzeit fließen zu lassen haben wir das Akka Framework mit Akka-Streams verwendet um letztlich die Daten über Websockets in den Browser des Anwenders zu pushen.
Um uns anschließend auf die Entwicklung zu konzentrieren, haben wir einen Blueprint des Architekturentwurfs erstellt.
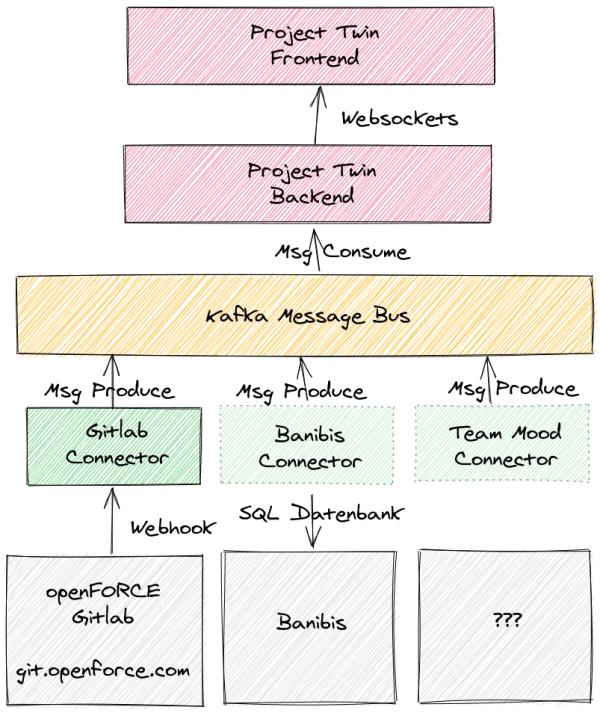
Team Work auf allen Ebenen
Damit haben wir alle Komponenten und deren Schnittstellen definiert und konnten mit der Arbeit beginnen. Durch die drei wesentlichen Komponenten
- Git Repository Anbindung,
- akka-http Server sowie
- den Browser Client
konnten wir uns die Arbeit sehr gut aufteilen. Ich kümmerte mich um die Git Anbindung, Christian um das Backend und Christian um das Frontend. Nebenbei haben Christian und ich auch noch Apache Kafka in Betrieb genommen. Dank verfügbarer Docker Container war das für unsere kleine Testumgebung wirklich schnell erledigt.
Im Gegensatz zum Projekt - der AI Foto-Webapp - an dem ich in unseren letzten openINNOVATION days gearbeitet habe, war das Zeitmanagement wesentlich entspannter. Es war bei weitem nicht so knapp wie beim letzten Mal.
Bessere Einteilung
Was wir diesmal besser gemacht haben war, dass wir uns grundsätzlich weniger vorgenommen haben auch mit dem fachlichen sowie technischen Thema besser vertraut waren. Einzig Akka Streams war noch neu für unsere Projektgruppe. Aber dank guter Dokumentation und einem reichen Fundus an Open Source Projekten, die wir auf Github gefunden haben konnten wir unsere Vorstellungen umsetzen. Ganz im Sinne eines agilen Vorgehens haben wir uns permanent abgestimmt, an welchen Tasks wir gerade arbeiten und wie wir uns gegenseitig helfen können!
Das Ergebnis
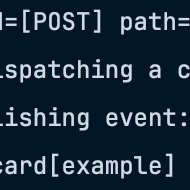
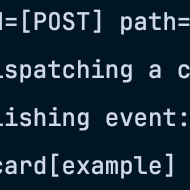
Am Ende haben wir unser Minimalziel erreicht. Wir hatten eine Anbindung an unseren Gitlab Server der über Webhooks mit unserem Konnektor kommuniziert, der wiederum die Gitlab Nachricht in unser Domänenmodell transformiert. Das Backend konsumiert über akka-streams die Nachrichten und pushed die Infos direkt über Websockets in den Browser des Anwenders.
Wir haben in dieser Woche übrigens beschlossen, aus dem kurzen Innovationsprojekt zunächst einmal ein internes Tool als Unterstützung unserer agilen Teams zu machen. Mal sehen ob da noch mehr daraus wird!