Ende September haben wir unsere zweiten openINNOVATION days in der openFORCE veranstaltet bei denen wir für zwei Tage eine Pause von unseren Kundenprojekten einlegten, um uns mit neuen Methoden in der Softwareentwicklung und neuen innovativen Technologien zu beschäftigen und vor allem unsere Fähigkeiten im Software-Projektalltag trainieren.
Nachdem meine Fotosammlung immer größer wird und ich nicht alle meine Fotos in der Google Cloud ablegen kann und will, habe ich mir überlegt- eine einfache Foto App zum Verwalten von großen Bildergalerien zu erstellen. Es gibt zwar schon einige Bildergalerien im Open Source-Umfeld, doch sind die wenigsten auf gute Skalierbarkeit in der Cloud ausgelegt. Außerdem sind die AI-Goodies, die die Foto-Apps von Google und Apple bereitstellen wirklich nett und hier wird es auch im Open Source-Umfeld weniger ergiebig. Und natürlich steht ja auch das Lernen von neuen Fähigkeiten im Vordergrund. Ich habe für das Projekt noch drei Mitstreiter gefunden. Andreas, Christian, Michail und ich stellten wir uns folgender Herausforderung.
- Erstellen einer simplen Foto Management Web-App
- Importieren von Fotos per API und über die Kommandozeile
- Verwendung vom Tensorflow AI Framework zur Klassifikation von Objekten in den Bildern
- Die Web-App soll die erkannten Objekte auf den Fotos ein- und ausblenden können.
Den theoretischen Hintergrund haben sich Christian und Andreas übrigens beim Uni-Lehrgang ("Innovationslehrgang Data Science und Deep Learning") geholt. Um das Thema maschinelles Lernen und AI im Allgemeinen kommt man mittlerweile einfach nicht mehr herum!
Wir haben also 2 Tage Zeit unser Ziel zu erreichen. Legen wir los!
Mittwoch
9:00. Wir einigen uns recht flott auf die wesentlichen Punkte die wir erreichen wollen und legen die wichtigesten Merkmale fest. Das Resultat sind die oben beschriebenen Funktionsblöcke, die unser MVP darstellen.
10:00. Nachdem wir wissen was wir bauen wollen brauchen wir einen Plan, wie wir das Ganze angehen. Also beginnen wir ein Diagramm zu zeichnen, innerhalb dessen wir die einzelnen Bausteine erfassen. Das Ergebnis ist die folgende Skizze der Software Architektur:
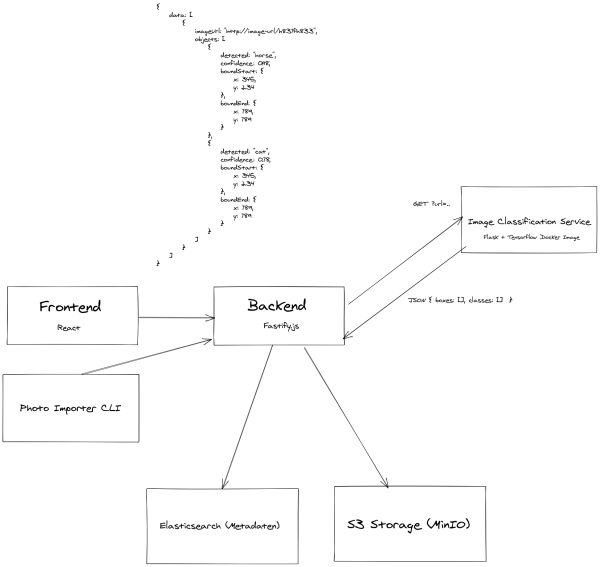
10:45. Nachdem die Zeit echt knapp bemessen ist, teilen wir uns auf und jeder übernimmt einen der großen Funktionsblöcke. Michail übernimmt das React Frontend, Christian taucht in die Python Welt ein und kümmert sich um die Objektklassifikation mittels Tensorflow. Auf das Backend stürzt sich Andreas und ich arbeite an dem Importer. Im Backend, Frontend und für den Importer einigen wir uns auf NodeJS und TypeScript. Damit wir aus TypeScript auf den AI-Teil zugreifen können haben wir beschlossen, diesen Teil in einer Rest API zu kapseln. Nachdem wir uns auch mit dem Setup nicht lange aufhalten wollen, packen wir alle Komponenten in Docker Container und orchestrieren sie mit einem einfachen docker-compose. Wie sich später zeigen wird, wird gerade dieses docker-compose nicht lange einfach bleiben :)
13:00. Pause. Wir sind erstaunt, wie weit wir schon gekommen sind. Das Frontend ist funktionstüchtig. Der Command Line Client ist schon in der Lage, ein Verzeichnis mit Fotodateien zu verarbeiten. Tensorflow läuft und wir haben einen Python Webserver mit Flask aufgesetzt. Wir haben auf unsere bewährten Blueprint Projekte gesetzt, das hat enorm viel Zeit gespart. Durch die Verwendung der offiziellen Docker Images der von uns verwendeten Komponenten haben wir uns auch nicht lange mit der Infrastruktur aufhalten müssen.
14:00. Weiter geht's! Die ersten technischen Tücken tauchen auf. Wir ändern unsere Arbeitsweise. Christian bleibt bei Tensorflow und arbeitet an der Object Detection. Andreas und ich beginnen zu pairen und arbeiten gemeinsam am Backend. Michael bleibt im Frontend fokussiert.
16:30. Wir haben das Gefühl, echt gut in der Zeit zu liegen. Das erste Foto wurde vom Importer in MinIO gespeichert (einem S3 kompatiblen Cloud Storage - Open Source). Die Tensorflow Komponente liest die Fotos von dort aus und startet die Object Detection. Wir haben ein Ergebnis, wissen aber noch nicht wie die Daten zu interpretieren sind. Wir bemerken, dass wir noch klären müssen, wie wir die erkannten Objekte speichern und wie wir die Daten zum Frontend bringen können. Also stecken wir alle kurz die Köpfe zusammen und definieren unser Model. In der Zwischenzeit haben wir auch verstanden was die Datenstrukturen die Tensorflow liefert bedeuten.
17:30. Läuft. Der Spaßfaktor ist gerade extrem hoch, aber die Konzentration lässt nach. Also Schluss für heute. Wir sind alle zufrieden mit dem Ergebnis des ersten Tages!
Donnerstag
9:00. Wir machen einen ersten Durchlauf mit einer größeren Anzahl an Fotos und stellen fest: Die Klassifikation mit Tensorflow benötigt auf unserer Hardware doch einiges an Zeit (1-4 Sekunden pro Foto). Wir haben den Ablauf von 1. Foto in MinIO speichern und 2. Klassifikation des Fotos sehr einfach und linear umgesetzt. Wir überlegen, ob es nicht Sinn macht, die beiden Arbeitsschritte asynchron durchzuführen. Klingt nach einer guten Idee. Wir entscheiden uns dazu, die Architektur noch einmal zu erweitern und einen Message Bus zu verwenden. Die Last wird dadurch zwar nicht geringer, aber die Antwortzeiten im UI und für den Importer können wir dadurch wesentlich beschleunigen. Also bauen wir Apache Kafka in das Projekt ein.
11:00. Kafka macht im Setup unerwartet Probleme. Aber nichts, das wir nicht lösen könnten. In Java/Scala Projekten haben wir Kafka bereits verwendet, aber die TypeScript und Python Schnittstelle, erweisen sich als widerspenstig. Gut, es gibt für TypeScript immerhin noch eine handvoll anderer Implementierungen zur Kafka Anbindung.
13:00. Michail ist mit dem Frontend so gut wie fertig. Es fehlt aber noch die Darstellung der gefundenen Objekte. Die Kafka-Anbindung läuft immer noch nicht. Die Spannung steigt langsam aber sicher, denn um 16:00 beginnt die Präsentation der Teams um Ihre Erkenntisse und Learnings vorzustellen. Wir teilen uns wieder auf. Ich bereite schon die Präsentation vor, Andreas arbeitet an der Kafka Integration, Michail arbeitet weiter am Frontend und Christian hilft sowohl im Backend als auch im Frontend mit.
15:00. Noch eine Stunde. Kafka Anbindung funktioniert immer noch nicht fehlerfrei. Das zu Beginn so einfache docker-compose ist nicht mehr so einfach. Gar nicht. Eigentlich ist es sogar ziemlich komplex geworden. Kafka braucht recht viel Infrastruktur und Netzwerk-Konfiguration in Docker. Vor allem der Zookeeper Cluster Manager ist nicht trivial zu konfigurieren. Wir sind uns ziemlich sicher, dass wir in der Software alles richtig gemacht haben und jetzt auch "gute" Bibliotheken verwenden. Wir haben aber nur noch eine Stunde Zeit und wollen unbedingt eine funktionierende Demo herzeigen. Die ersten Ideen machen sich breit, ob wir uns nicht als letzte Gruppe zur Präsentation melden sollten, um noch ein paar Minuten mehr Zeit zu haben.? Das erinnert uns dann doch zu sehr an folgende Situation:
youtube: https://www.youtube.com/embed/75wa8Lx4yc4?rel=0
15:30. Wir entscheiden uns, Kafka wieder auszubauen und die Demo auf 10 Bilder zu beschränken. Mit dieser Menge ist die Zeit für die Klassifizierung kein Problem. Die Präsentation selbst ist längst fertig und damit arbeiten wir alle wieder zusammen. Wir beginnen das ganze Setup noch einmal zu testen und alle unsere Bugfixes und Changes in unser Git Repo einzuspielen.
15:45. Das Frontend ist jetzt final. Die Ergebnisse der Klassifikation können dargestellt werden und es schaut richtig gut aus. Allerdings funktioniert der Foto Importer durch eine der letzten Änderungen nicht mehr.
15:50. Der Foto Importer funktioniert noch immer nicht. Das Importieren über unsere Rest API aber schon. Wir entschließen uns diese für die Demo zu verwenden.
15:55. Mit der API läuft jetzt alles auf Christians Rechner rund. Andreas und ich versuchen immer noch, den Importer zum Laufen zu bekommen. Eigentlich sollte alles funktionieren.
15:57. Durch die Analyse des Importers findet Andreas auch das Problem, warum Kafka nicht funktioniert hat. Er macht kurzerhand den Vorschlag, das ganze doch noch einzubauen, im Grunde funktionert es jetzt.
15:58. Der Rest des Teams findet die Idee gar nicht sooo gut. Wir entscheiden uns gemeinsam, Kafka doch nicht wieder einzubauen.
15:59. Demo läuft. Kafka ist draußen. Warum der Foto Importer nicht mehr funktionierte ist uns jetzt auch klar!
15:59:55. Demo läuft jetzt auch auf einem zweiten Computer. Inklusive dem Importer! Wir entscheiden uns in den letzten 5 Sekunden, keine entscheidenden Änderungen mehr am Demo-Aufbau durchzuführen.
16:00. Wir wechseln in den Team Raum und freuen uns darauf, das Ergebnis der letzten beiden Tage im gesamten openFORCE Team vorzustellen!
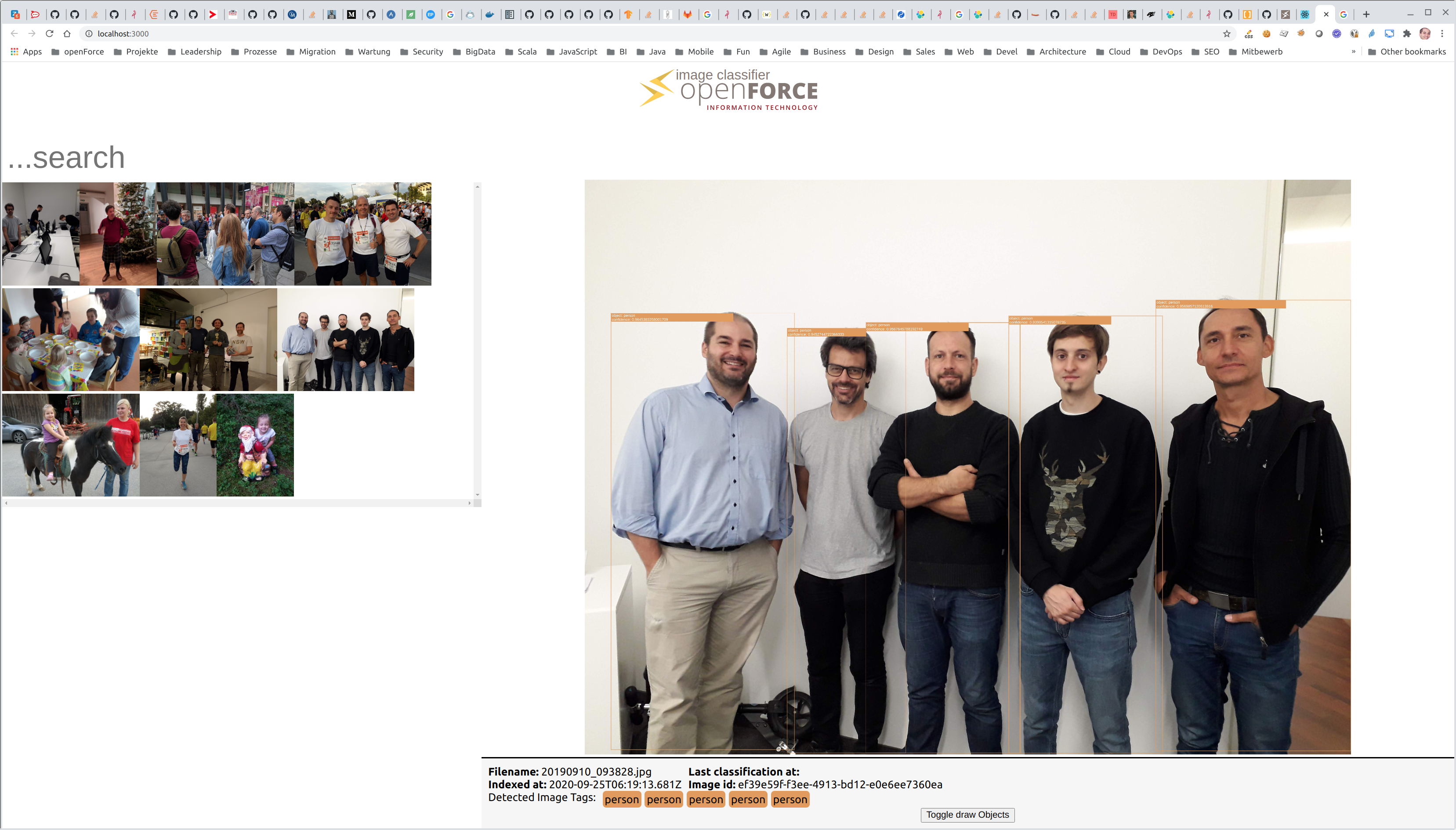
Hier ein Beispielfoto mit einem Teil unseres Teams - immerhin werden wir als "Personen" erkannt:

In den beiden Tagen haben wir unglaublich viel gelernt. Nicht nur im technischen Bereich. Fokus, Zusammenarbeit und das Befolgen eines gemeinsamen Plans mit laufender Abstimmung im Team waren ein wesentlicher Erfolgsfaktor und steigern den Spaßfaktor enorm. Daneben haben wir noch ein paar Punkte mitgenommen und gelernt.
- Tensorflow ist wirklich cool!
- Man muss kein Data Scientist sein, um Tensorflow nutzen zu können (solange man keine eigenen Modelle entwickelt)!
- Man braucht ein polyglottes Entwicklungsteam (außer man entwickelt alles in Python) denn: Python ist im AI Bereich Pflicht!
- Infrastruktur ist hart!
- Verwendet man bestehende, vortrainierte Modelle kann man schon in sehr kurzer Zeit, gute Ergebnisse erzielen.
- Will man eigene Modelle entwickeln braucht man vor allem zwei Dinge.
- Extrem viel Storage. Das von uns verwendete Model wurde mit knapp 450.000 Fotos trainiert!
- Extrem viel CPU oder noch besser GPU. Will man ernsthaft AI Modelle entwickeln gibt es überhaupt Spezialhardware um diese Modelle zu trainieren.
Ausblick
Für die nächsten openINNOVATION days haben wir noch jede Menge Ideen. So kann das aktuelle Modell etwa 90 Objekte in Fotos erkennen (Personen, Tisch, Stuhl, Pferd,...). Im nächsten Schritt könnten wir Gesichtserkennung (Identifikation von Personen) einbauen und aus den Metadaten der Fotos noch komplexere Suchanfragen umsetzen.